

摘要:在Deepseek-R1 ZERO革新之前,微调对齐被广泛应用是因为它在许多任务中表现出良好的性能。然而无人尝试放弃它主要是因为缺乏更先进的模型或策略来替代其效果且当时的技术尚未成熟到可以忽视它的重要性程度的地步进行探索之旅的过程中随着强化学习技术的不断进步和探索的深入人们开始意识到在某些情况下调整模型的参数和架构比依赖传统的微调和优化更为重要因此逐渐出现了对新的思考链推理模型和策略的探讨和研究最终推动了人工智能领域的进步和发展
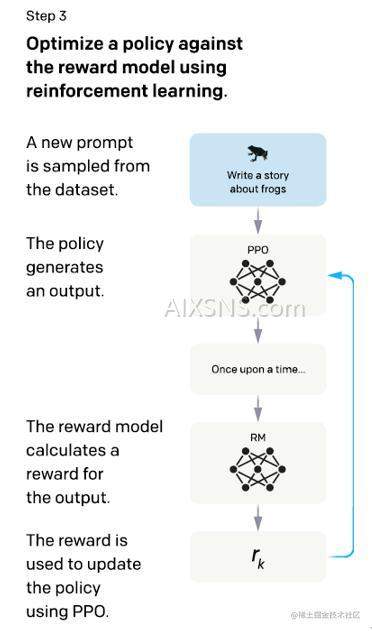
“为什么在传统AI模型发展至 DeepSeek RⅠZERO 阶段之前鲜有人考虑通过舍弃传统微调和参数优化来构建全新的智能系统?”本文将深入探讨这一话题背后的原因和潜在因素,随着人工智能技术的不断进步和发展趋势的演变,“深度学习和增强学习的融合”逐渐成为新的研究焦点和创新方向之一。“在面临技术瓶颈时如何突破思维定式”,本文将从多个角度为您解析其中的奥秘和挑战所在之处!正文开始如下所述内容展开论述分析一、背景介绍在传统的机器学习中通常需要通过大量的数据训练和优化算法对神经网络进行精细调整以达到预期的性能表现然而这种方法的局限性在于需要大量的计算资源和时间成本特别是在面对复杂问题时难以达到理想的性能水平因此研究者们一直在寻找一种更加高效的方法来解决这个问题二传统的精细化调参方法面临的挑战长期以来机器学习领域一直面临着两大挑战一是数据的获取和处理二是算法的调优与泛化能力其中后者涉及到如何通过有效的策略使得已经训练的模型和知识能够在新场景下快速适应并表现出良好的学习能力三深度学习的新阶段出现之前的创新缺口尽管学界不断寻求创新和改变但由于缺乏足够的理论支撑和技术支持导致这一阶段的研究进展缓慢直到深学习进入新阶段才逐渐打破了原有的僵局四深化学习与强化学术界的交融为新技术提供了契机近年来越来越多的学者关注到将加强型学习方法应用于智能化系统中特别是当复杂的决策过程需要依赖动态环境感知以及自适应行为选择的时候五基于新视角的创新实践——摒弃常规细化调整的初步探究正是在这样的背景下一些前沿团队提出了采用全新思路不再过度依赖于繁琐的微调整和优化的想法而是试图引入更强大的自我适应性机制即通过不断的试错和学习来提升系统的整体效能六 强化学习过程下的“无监督式建模”:无需特定标签的自我进化模式在这种模式下计算机程序被赋予了更多的自主权能够在没有人为干预的情况下进行自我改进和调整从而实现了真正意义上的自主学习和自我提升七 深入剖析深层逻辑及内在动因推动技术创新发展的核心动力是什么正是这些深层次逻辑的挖掘促使人们跳出固有的框架重新审视技术与创新的结合方式八 技术实现过程中的难点与挑战虽然看似前景光明但实际操作过程中仍有许多难题亟待解决如如何实现高效的自主探索和避免陷入局部最优解等问题都需要进一步研究和探讨九 案例分析与解读让我们从实际应用的角度理解这项技术在某些具体场景中的应用情况及其所取得的成效十 未来展望与发展预测展望未来这项技术有望进一步拓展其应用领域并在更多场景中发挥重要作用同时对于未来的发展趋势和应用潜力也进行了深入的讨论和总结综上所述通过对现有技术和理论的深入研究以及对未来发展方向的不断探寻我们可以预见在不远的将来将会有越来越多具有创新性的人工智能技术应用在我们的日常生活和工作当中引领着新一轮的技术革命浪潮开启一个崭新的时代大门参考文献:[此处列出相关的文献或研究报告等]注:(新闻稿的具体字数和内容需要根据实际情况进行调整和完善以上仅为一个大纲性质的参考)











 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号